Zhuo Su | 苏卓
 |
I am a Tech Lead and Researcher at ByteDance, working on Human-Centric AI. My work centers on building AI systems for human motion capture, performance capture, avatar generation, and immersive interaction, with the goal of bridging the physical and virtual worlds. More broadly, I am interested in machine intelligence grounded in human experiences, capable of understanding people and modeling human behaviors, and in translating it into real-world interactive systems involving humans, AI agents, robots, and worlds. Prior to joining ByteDance, I worked at Tencent as a Senior Researcher through the Special Recruitment Talents Program (技术大咖). Before that, I graduated from Tsinghua University, where I was fortunate to be supervised by Qionghai Dai and Lu Fang, and collaborated closely with Yebin Liu and Lan Xu. |
Research
Interests
- Human-Centric AI
- Human Perception & Understanding
- Human/Embodied Foundation Models
- Avatar Creation & Systems
- Motion Capture / Generation
- Generative Humans / Worlds
- Neural Rendering / Relighting
- Performance Capture
Services
- Conference Reviewer: CVPR, ICCV, ECCV, SIGGRAPH, SIGGRAPH ASIA, NeurIPS, ICLR, ICML, AAAI, AAAI-AIA, IEEE VR, 3DV, ACMMM, WACV, AISTATS, ...
- Journal Reviewer: ACM TOG, IEEE TVCG, IEEE TIP, TMLR
- Program Committee Member: CSIG Technical Committee on 3D Vision, AAAI 2026, AAAI 2026 AI Alignment Track, ACMMM 2026
- Workshop Organizer: SIGGRAPH 2025, SIGGRAPH 2026
Let's Collaborate!
- Open to discussions from academia and industry on tech implementation and real-world impact.
- Looking for full-time collaborators and research interns. Contact me via email if interested.
Publication
-
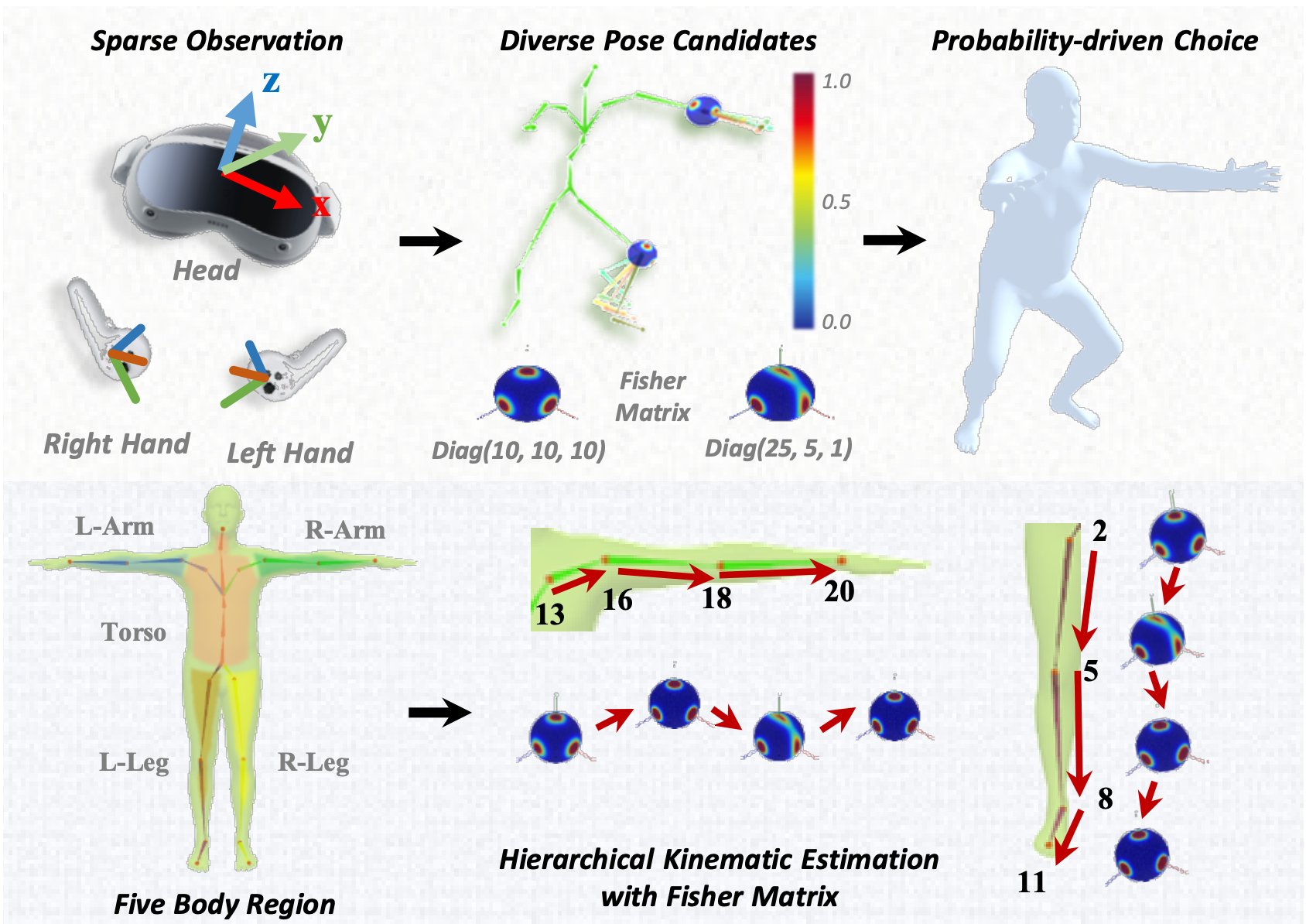
FisherPoser: Human Motion Estimation from Sparse Observations with Hierarchical Region-Wise Fisher-Matrix Uncertainty Modeling
Songpengcheng Xia, Qingyu Zhang, Zhuo Su, Jiarui Yang, Zengyuan Lai, Qi Wu, Ling Pei
CVPR 2026
We propose FisherPoser, a probabilistic framework for full-body motion estimation from sparse VR observations. By modeling joint orientations as Matrix-Fisher distributions on SO(3) and employing a hierarchical region-wise decoder, our method explicitly resolves one-to-many ambiguity, achieving highly accurate and jitter-free tracking with well-calibrated uncertainty.
-

POLAR: A Portrait OLAT Dataset and Generative Framework for Illumination-Aware Face Modeling
Zhuo Chen*, Chengqun Yang*, Zhuo Su‡ (Corresponding Author), Zheng Lv, Jingnan Gao, Xiaoyuan Zhang, Xiaokang Yang, Yichao Yan‡
CVPR 2026 Oral
We introduce POLAR, a large-scale, physically calibrated OLAT dataset with 200+ subjects captured under 156 lighting directions, multiple views, and diverse expressions. Based on this, we propose POLARNet, a flow-based model that predicts per-light OLAT responses from a single portrait, capturing fine-grained, direction-aware illumination while preserving identity.
-
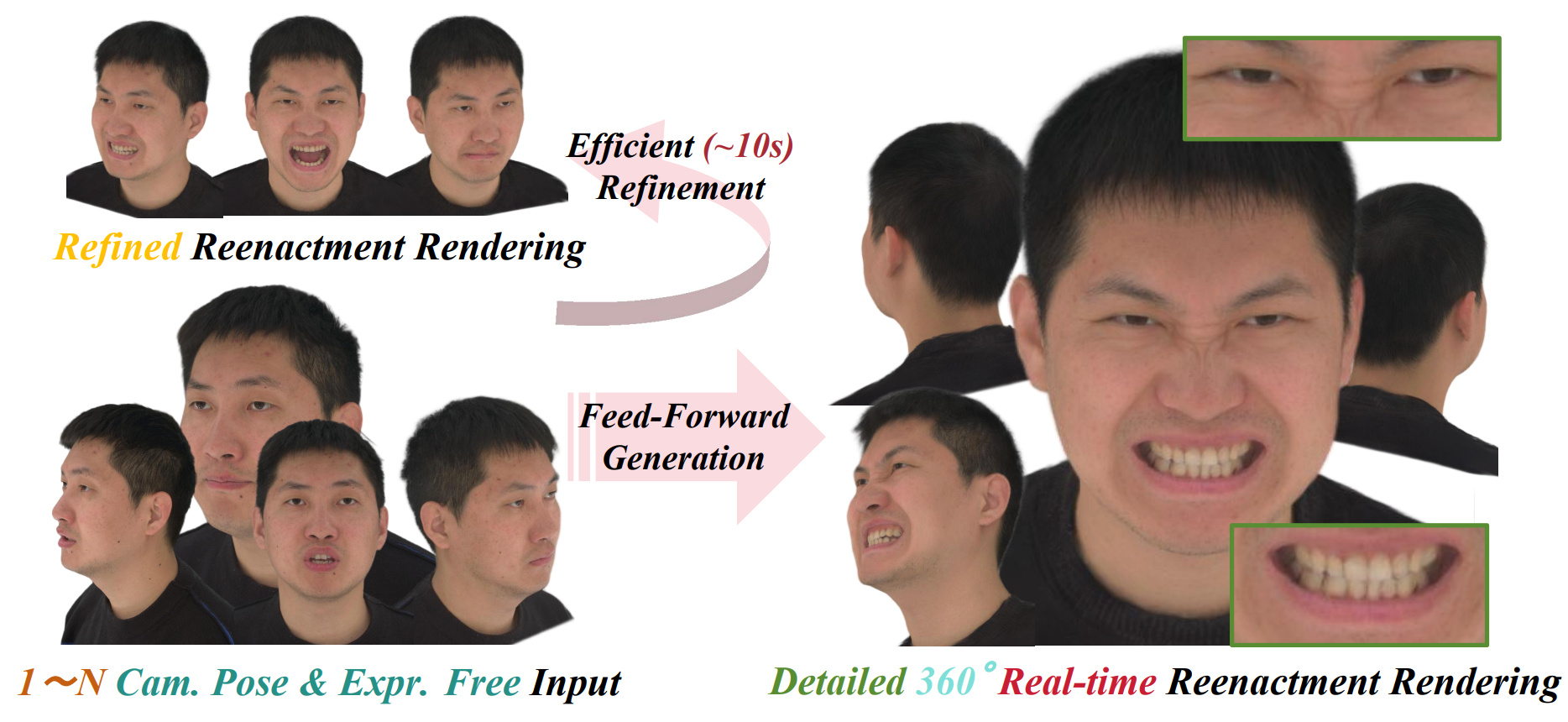
FlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Cheng Peng*, Zhuo Su*‡ (Corresponding Author), Liao Wang*, Chen Guo, Zhaohu Li, Chengjiang Long, Zheng Lv, Jingxiang Sun, Chenyangguang Zhang, Yebin Liu‡
CVPR 2026
We present FlexAvatar, a flexible large reconstruction model that generates high fidelity animatable 3D head avatars with detailed dynamic deformations from single or sparse images without requiring camera poses or expression labels, using a transformer based canonical representation together with a UV conditioned lightweight decoder for real time expression aware detail synthesis.
-
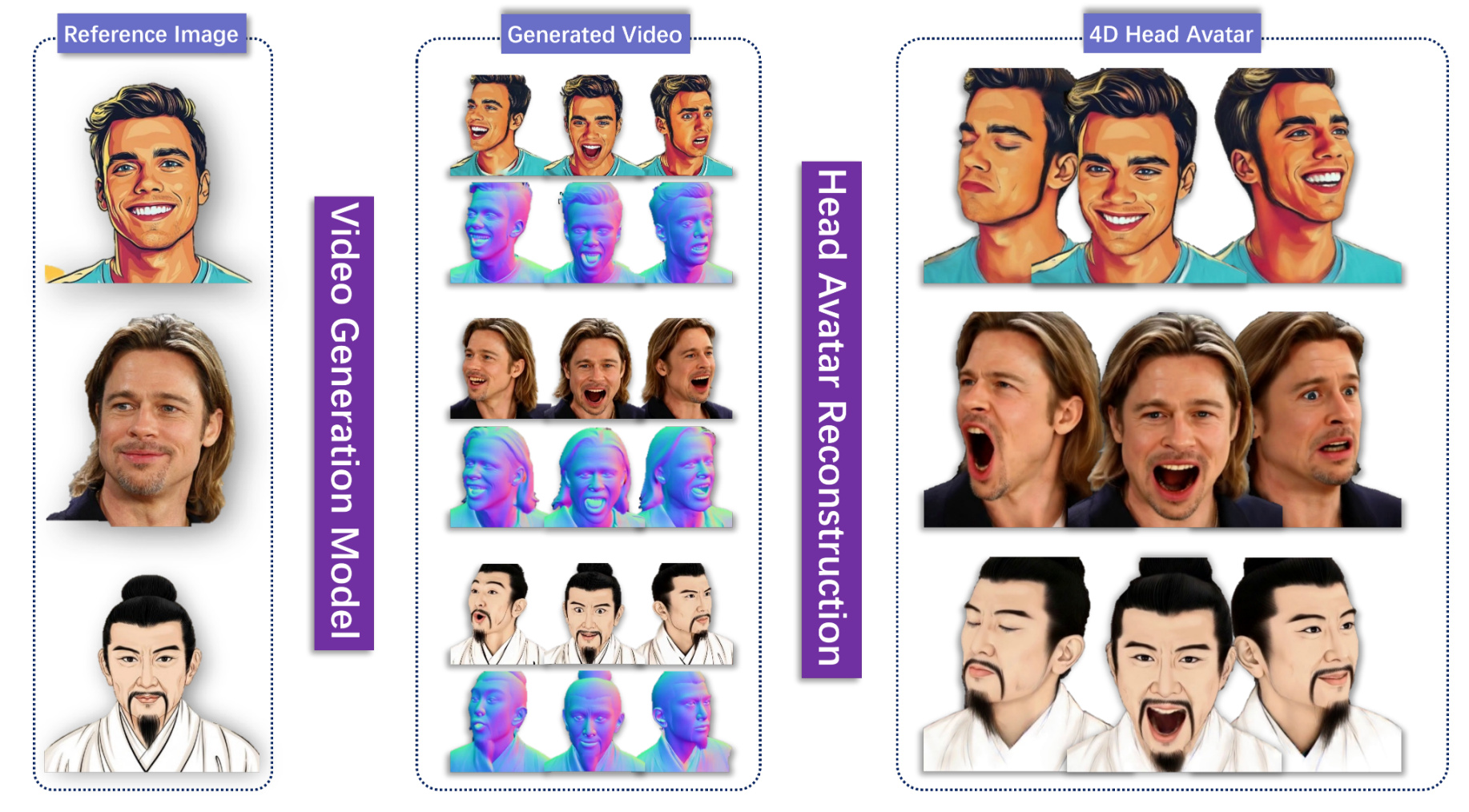
GeoDiff4D: Geometry-Aware Diffusion for 4D Head Avatar Reconstruction
Chao Xu, Xiaochen Zhao, Xiang Deng, Jingxiang Sun, Donglin Di, Zhuo Su†(Project Lead), Yebin Liu‡
CVPR 2026
We propose a portrait video generation framework from a single portrait image, which jointly synthesizes images and surface normals while learning pose-free expression representations for accurate geometry and real-time rendering, with optional integration into a 3D Gaussian-based avatar.
-

Relightable and Animatable Gaussian Head Avatar from Monocular Videos
Zhuo Chen*, Yichao Yan‡, Jingnan Gao, Zhuo Su†(Project Lead), Chao Wen, Zhaohu Li, Yuhao Cheng, Xueying Lee, Yutong Leng, Yikun Zeng, Guidong Wang, Xiaokang Yang
TVCG 2026
We propose a method for relightable avatar reconstruction from a monocular video under unknown lighting, using a disentangled 3D Gaussian representation and a diffusion model to predict canonical lighting and material maps for improved rendering and view consistency.
-

Director: Instance-aware Gaussian Splatting for Dynamic Scene Modeling and Understanding
Yuheng Jiang, Yiwen Cai, Zihao Wang, Yize Wu, Sicheng Li, Zhuo Su, Shaohui Jiao, Lan Xu
arXiv 2026
We propose Director, a unified spatio-temporal Gaussian representation for dynamic scene modeling that jointly enables temporally coherent 4D reconstruction, high-fidelity human rendering, and instance-level semantic understanding through language-aligned semantic supervision, motion refinement, and geometry-aware regularization.
-
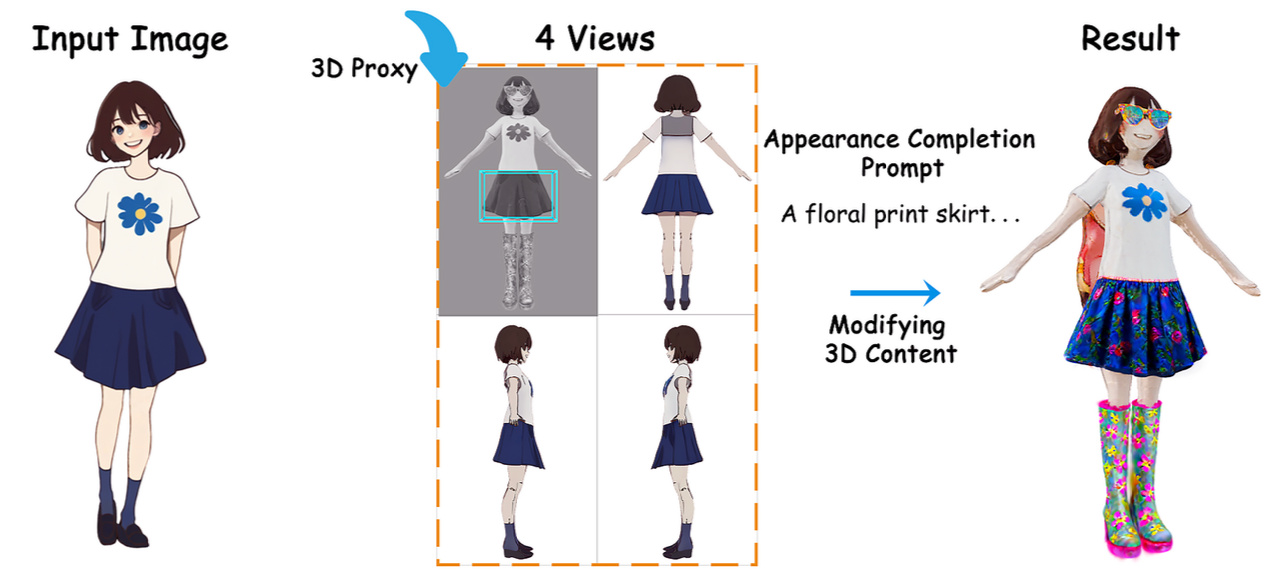
InterCoser: Interactive 3D Character Creation with Disentangled Fine-Grained Features
Yi Wang*, Jian Ma*, Zhuo Su†(Project Lead), Guidong Wang, Jingyu Yang, Yu-Kun Lai, Kun Li‡
AAAI 2026 Oral
We present an interactive AIGC framework for disentangled 3D character creation, supporting sketch-based clothing transfer and 3D-proxy-guided part editing. Our method leverages geometry-aware 3D Gaussian reconstruction to ensure high-fidelity, editable avatars with fine-grained control.
-

DreamCoser: Controllable Layered 3D Character Generation and Editing
Yi Wang*, Jian Ma*, Zhuo Su†(Project Lead), Guidong Wang, Yu-Kun Lai, Kun Li‡
SIGGRAPH Asia 2025 Technical Communications
We present DreamCoser, an AIGC framework for controllable, layered 3D character generation and sketch-based editing, enabling part-level customization from a single image.
-

Topology-Aware Optimization of Gaussian Primitives for Human-Centric Volumetric Videos
Yuheng Jiang, Chengcheng Guo, Yize Wu, Yu Hong, Shengkun Zhu, Zhehao Shen, Yingliang Zhang, Shaohui Jiao , Zhuo Su, Lan Xu, Marc Habermann, Christian Theobalt
SIGGRAPH Asia 2025
We propose TaoGS, a framework that disentangles motion and appearance for coherent volumetric video under topological variation, with codec-friendly compression for scalable high-fidelity rendering.
-
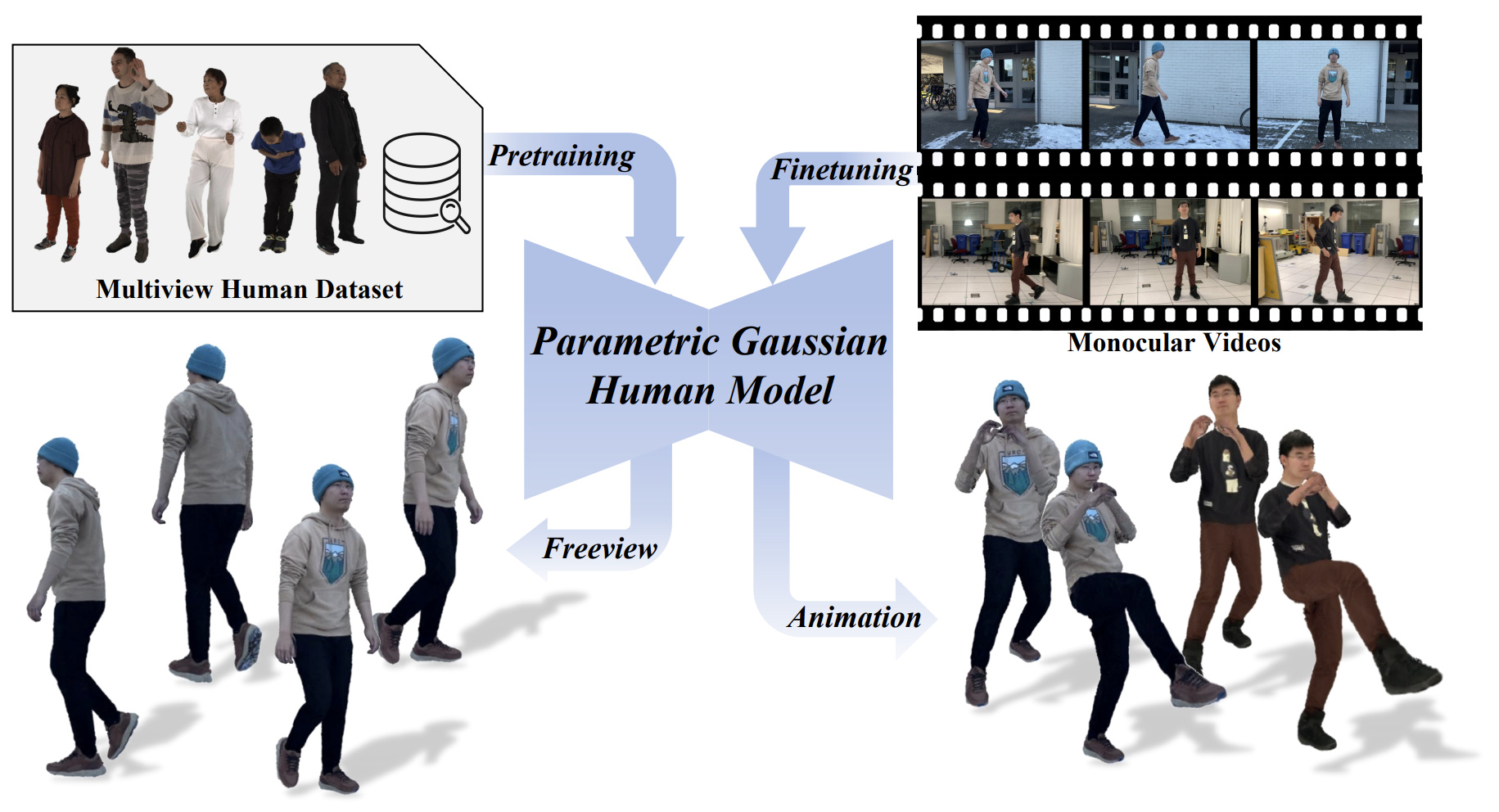
Parametric Gaussian Human Model: Generalizable Prior for Efficient and Realistic Human Avatar Modeling
Cheng Peng, Jingxiang Sun, Yushuo Chen, Zhaoqi Su, Zhuo Su, Yebin Liu
3DV 2026
We present PGHM, a generalizable and efficient framework that integrates human priors into 3DGS for fast and high-fidelity avatar reconstruction from monocular videos.
-

SMGDiff: Soccer Motion Generation using Diffusion Probabilistic Models
Hongdi Yang, Chengyang Li, Zhenxuan Wu, Gaozheng Li, Jingya Wang, Jingyi Yu, Zhuo Su, Lan Xu
ICCV 2025
We introduce SMGDiff, a novel two-stage framework for generating real-time and user-controllable soccer motions. Our key idea is to integrate real-time character control with a powerful diffusion-based generative model, ensuring high-quality and diverse output motion.
-
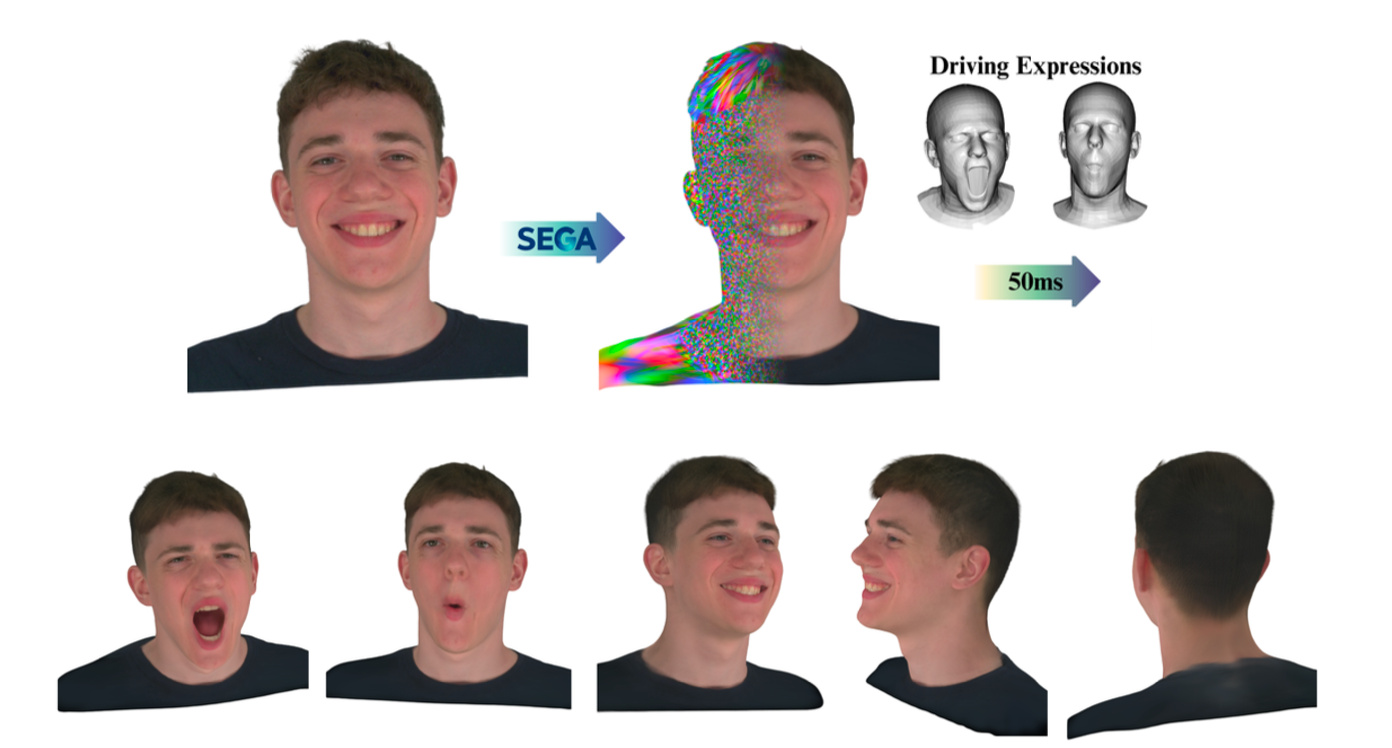
SEGA: Drivable 3D Gaussian Head Avatar from a Single Image
Chen Guo*, Zhuo Su*‡ (Corresponding Author), Jian Wang , Shuang Li, Xu Chang, Zhaohu Li, Yang Zhao, Guidong Wang, Ruqi Huang‡
arXiv 2025
We propose SEGA, a novel approach for Single-imagE-based 3D drivable Gaussian head Avatar creation that combines generalized prior models with a new hierarchical UV-space Gaussian Splatting framework.
-
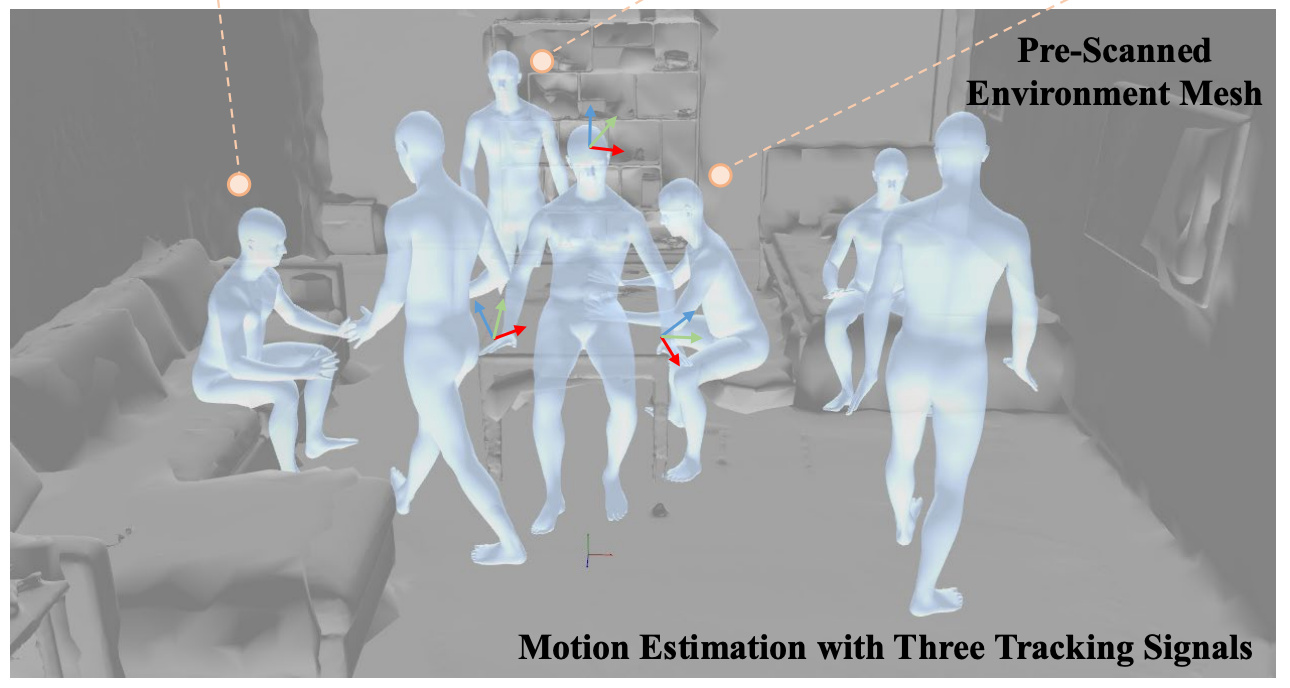
EnvPoser: Environment-aware Realistic Human Motion Estimation from Sparse Observations with Uncertainty Modeling
Songpengcheng Xia, Yu Zhang, Zhuo Su† (Project Lead), Xiaozheng Zheng, Zheng Lv, Guidong Wang, Yongjie Zhang, Qi Wu, Lei Chu, Ling Pei‡
CVPR 2025
We propose EnvPoser, a two-stage method using sparse tracking signals and pre-scanned environment from VR devices to perform full-body motion estimation and handle the multi-hypothesis nature with uncertainty-aware and environmental constraint integration.
-

RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance
Yuheng Jiang, Zhehao Shen, Chengcheng Guo, Yu Hong, Zhuo Su, Yingliang Zhang, Marc Habermann‡, Lan Xu‡
CVPR 2025
We present RePerformer, a Gaussian-based representation for high-fidelity volumetric video playback and re-performance. Via Morton-based parameterization, our method enables efficient rendering. A semantic-aware alignment module and deformation transfer enhance realistic motion re-performance.
-
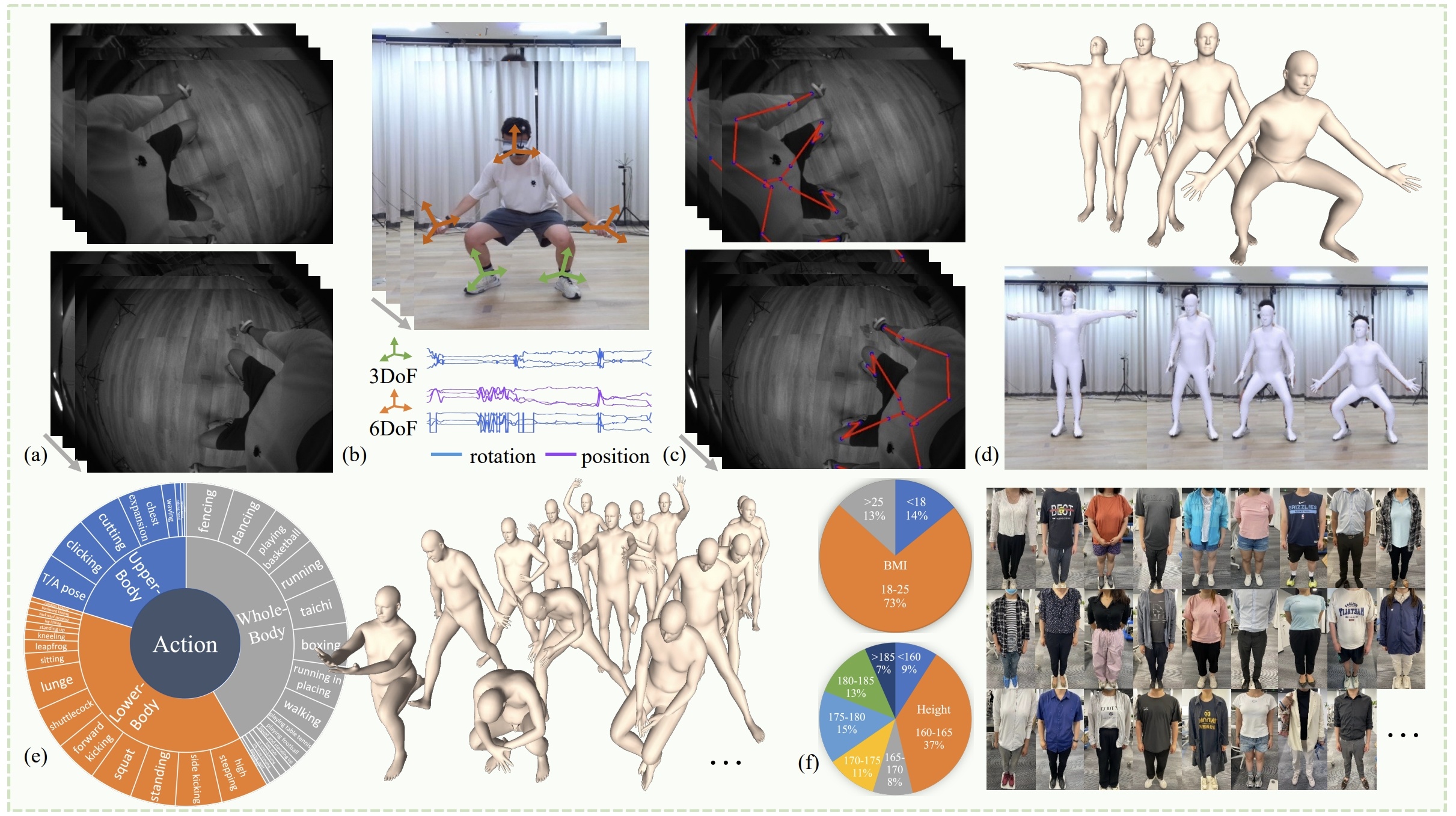
EMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
Zhen Fan*, Peng Dai*, Zhuo Su*, Xu Gao, Zheng Lv, Jiarui Zhang, Tianyuan Du, Guidong Wang, Yang Zhang
AAAI 2025
We introduce EMHI, a dataset combining stereo images from headsets and IMU data for egocentric human motion capture in VR. It includes 28.5 hours of data from 58 subjects. We also propose MEPoser, a method that effectively uses this multimodal data for improved pose estimation.
-
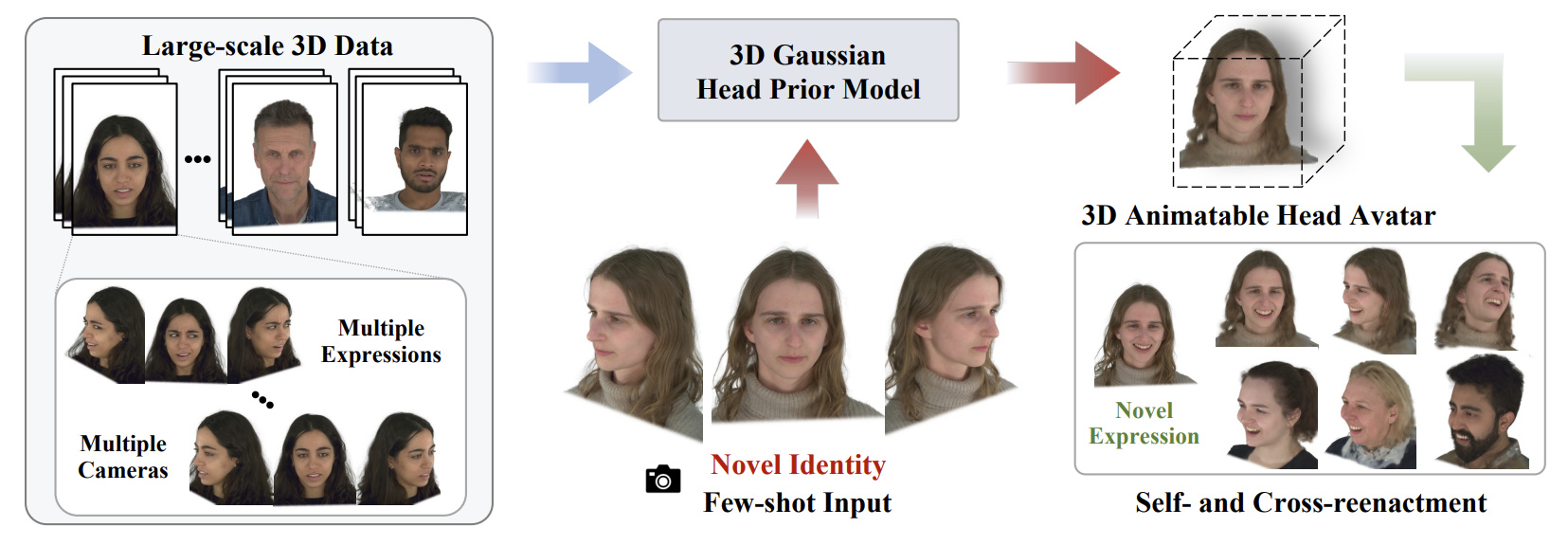
HeadGAP: Few-shot 3D Head Avatar via Generalizable Gaussian Priors
Xiaozheng Zheng, Chao Wen, Zhaohu Li, Weiyi Zhang, Zhuo Su, Xu Chang, Yang Zhao, Zheng Lv, Xiaoyuan Zhang, Yongjie Zhang, Guidong Wang, Lan Xu
3DV 2025
We propose a 3D head avatar creation method that generalizes from few-shot in-the-wild data. By using 3D head priors from a large-scale dataset and a Gaussian Splatting-based network, our approach achieves high-fidelity rendering and robust animation.
-
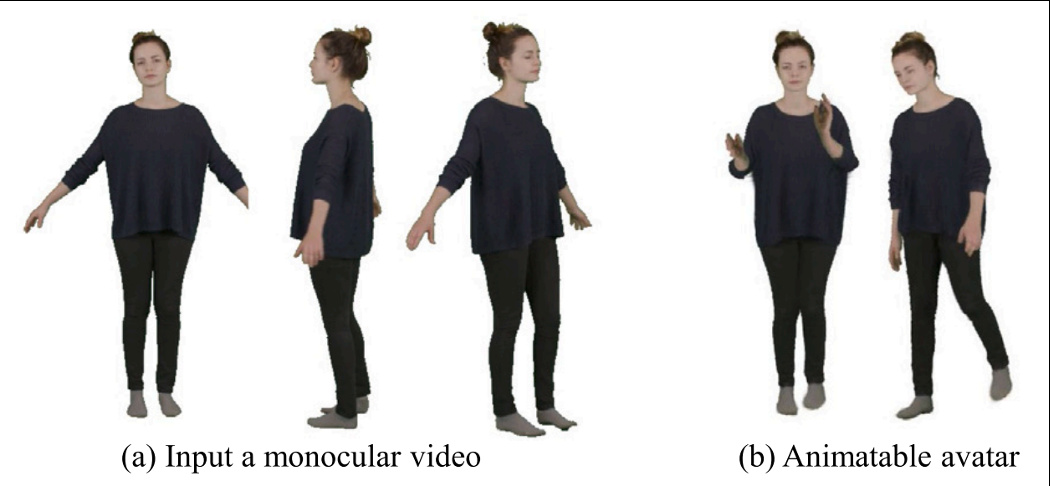
LoGAvatar: Local Gaussian Splatting for human avatar modeling from monocular video
Jinsong Zhang, Xiongzheng Li, Hailong Jia, Jin Li, Zhuo Su, Guidong Wang, Kun Li‡
CAD 2025
We present LoGAvatar, a hierarchical 3D Gaussian Splatting framework that reconstructs editable avatars from monocular videos by anchoring local Gaussians to a human template and using a convolution-based texture atlas for real-time rendering and intuitive editing.
-
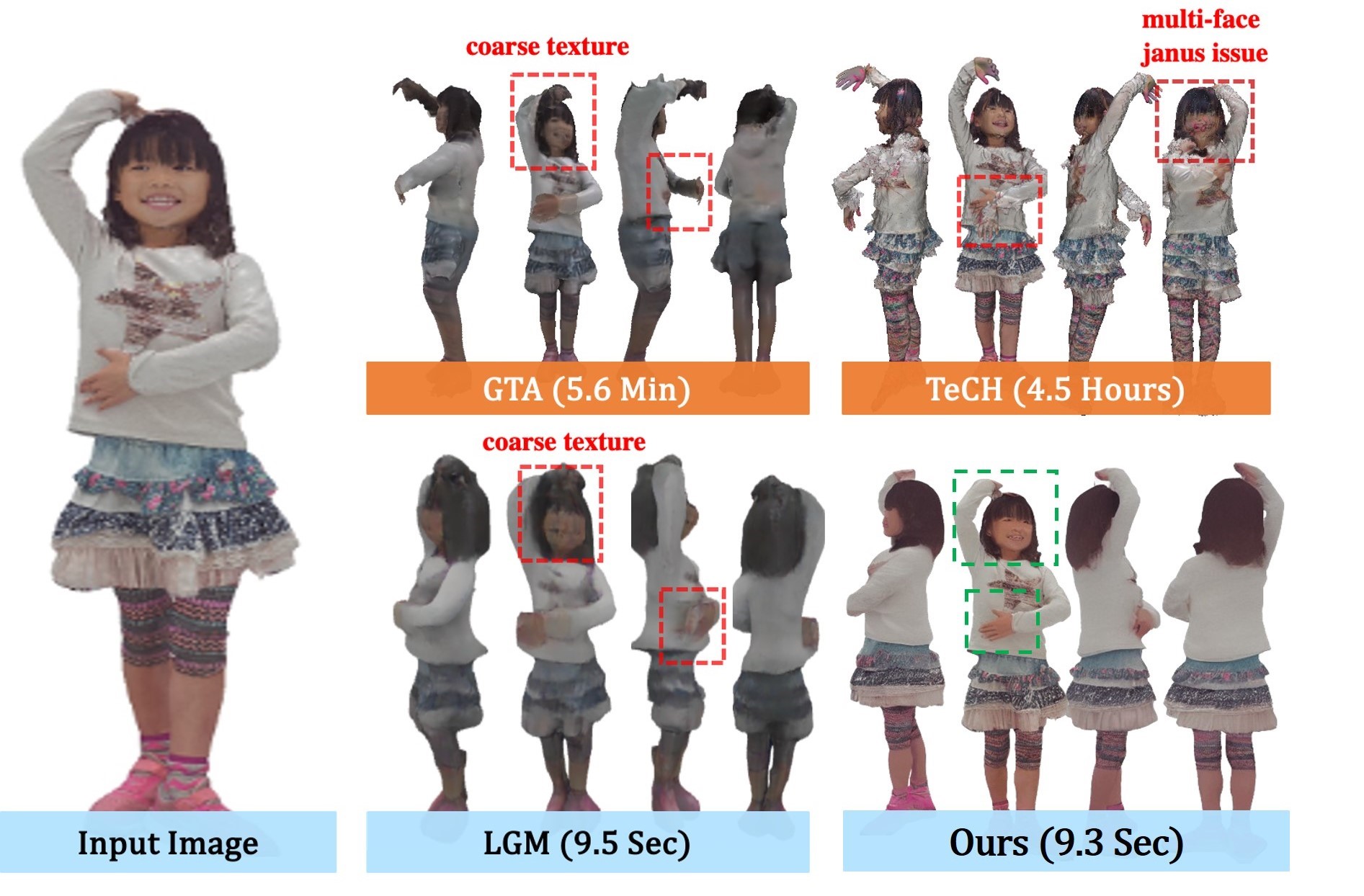
HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Panwang Pan*, Zhuo Su* † (Project Lead), Chenguo Lin*, Zhen Fan, Yongjie Zhang, Zeming Li, Tingting Shen, Yadong Mu, Yebin Liu‡
NeurIPS 2024
We propose HumanSplat, a method that predicts the 3D Gaussian Splatting properties of a human from a single input image in a generalizable way. It utilizes a 2D multi-view diffusion model and a latent reconstruction transformer with human structure priors to effectively integrate geometric priors and semantic features.
-

HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
Yuheng Jiang, Zhehao Shen, Penghao Wang, Zhuo Su, Yu Hong, Yingliang Zhang, Jingyi Yu, Lan Xu
CVPR 2024.
We present an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage, in which our core intuition is to marry the 3D Gaussian representation with non-rigid tracking.
-
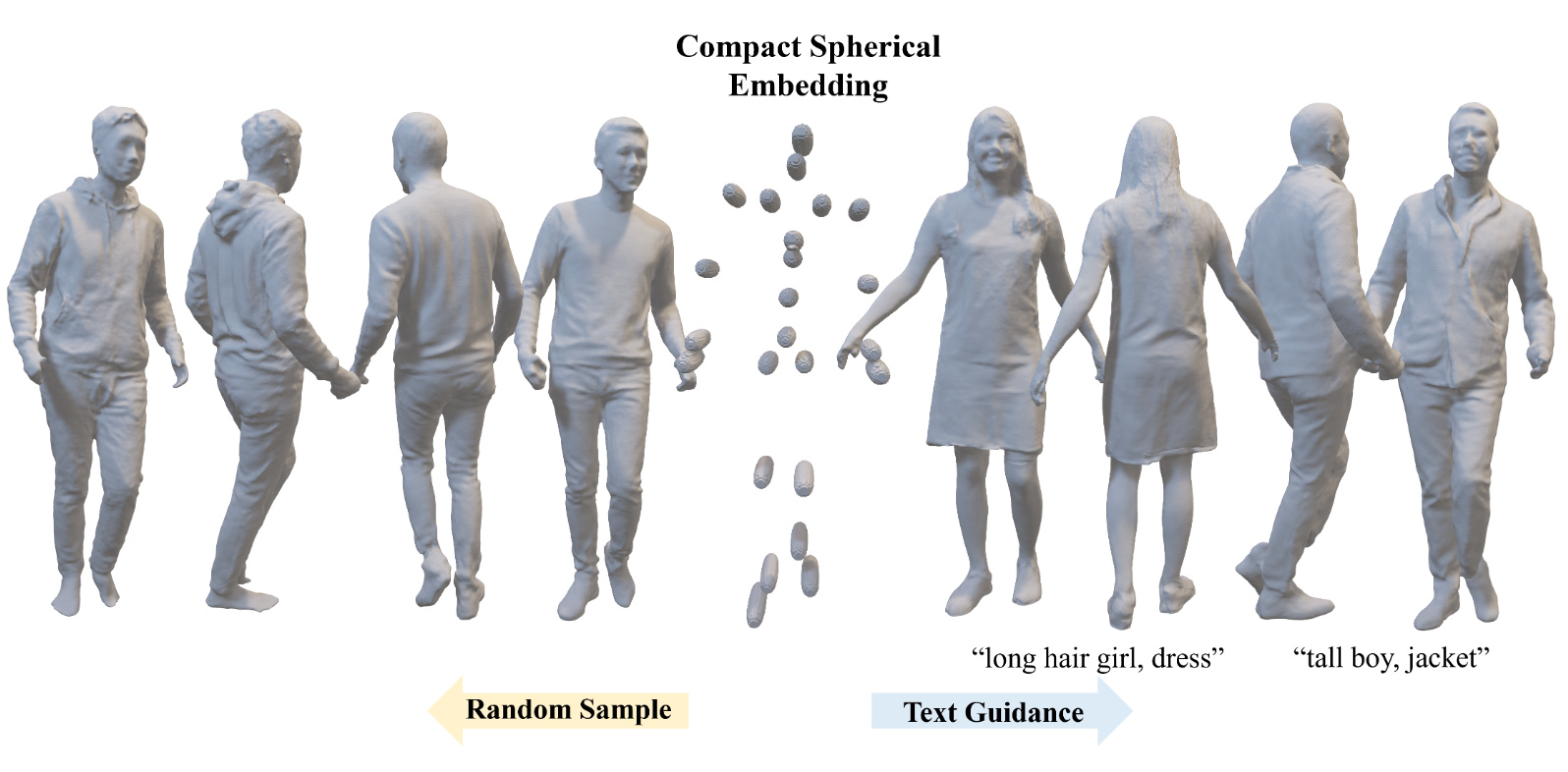
Joint2Human: High-quality 3D Human Generation via Compact Spherical Embedding of 3D Joints
Muxin Zhang, Qiao Feng, Zhuo Su, Chao Wen, Zhou Xue, Kun Li
CVPR 2024
We introduce Joint2Human, a novel method that leverages 2D diffusion models to generate detailed 3D human geometry directly, ensuring both global structure and local details.
-
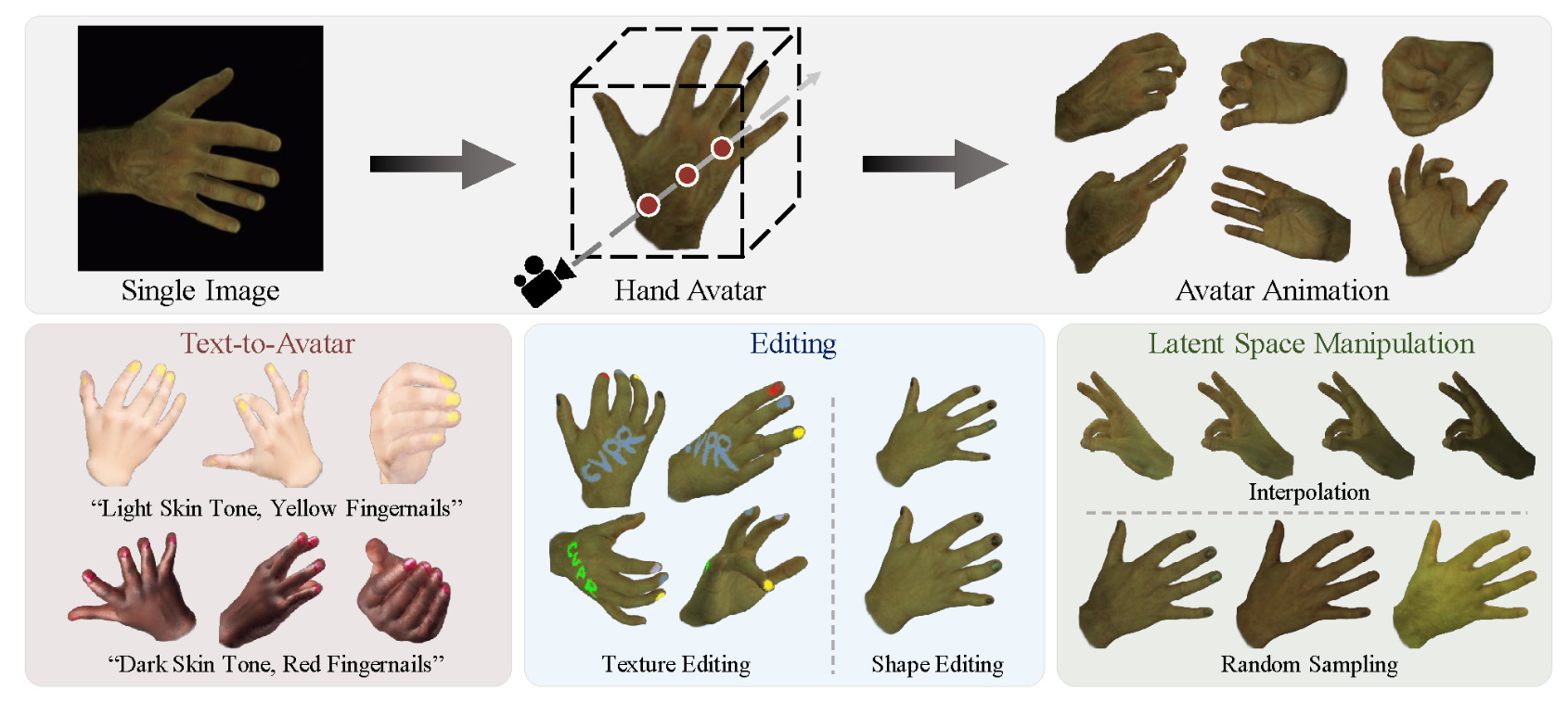
OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
Xiaozheng Zheng, Chao Wen, Zhuo Su, Zeran Xu, Zhaohu Li, Yang Zhao, Zhou Xue
CVPR 2024
OHTA is a novel approach capable of creating implicit animatable hand avatars using just a single image. It facilitates 1) text-to-avatar conversion, 2) hand texture and geometry editing, and 3) interpolation and sampling within the latent space.
-
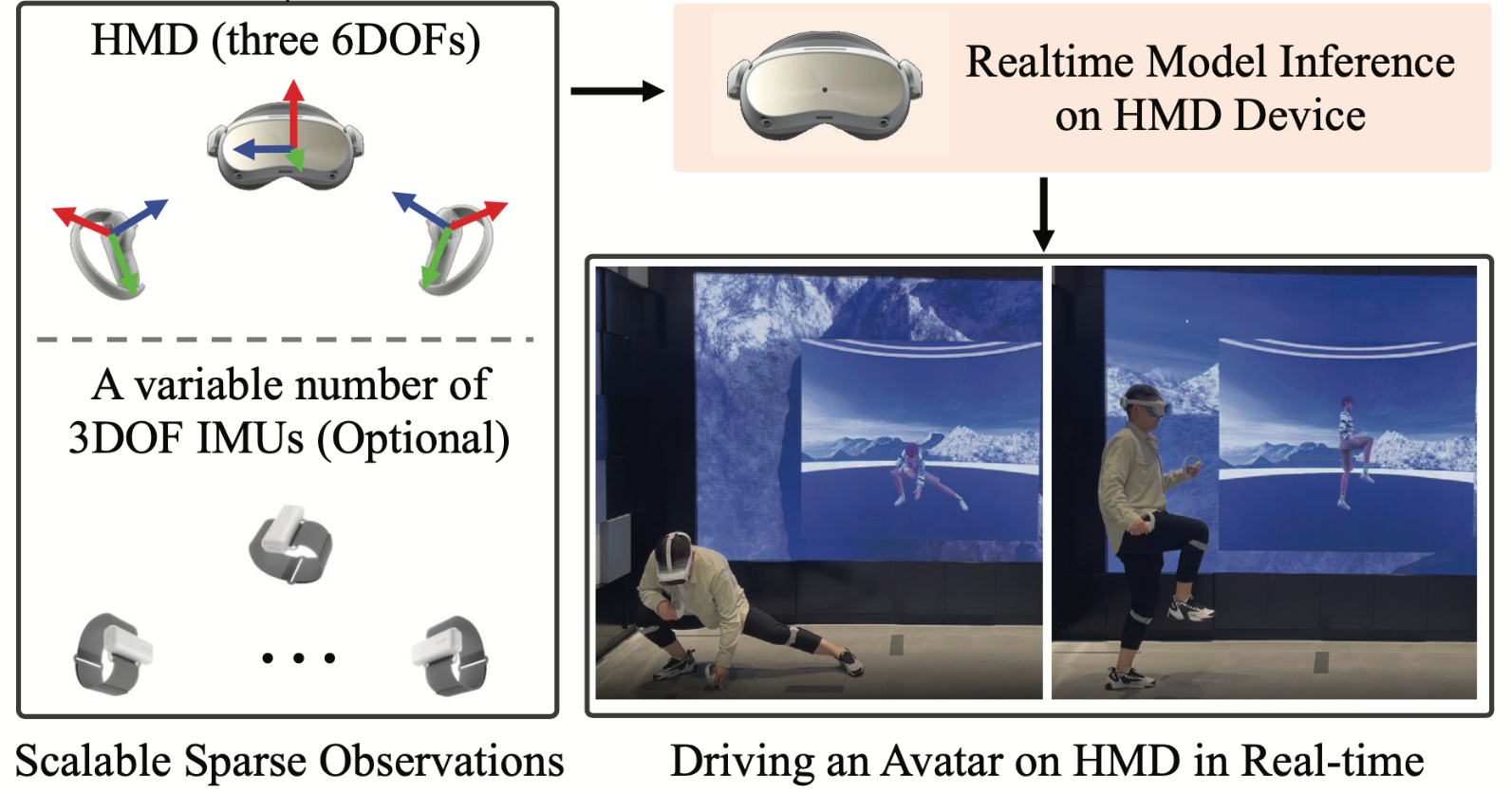
HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations
Peng Dai, Yang Zhang, Tao Liu, Zhen Fan, Tianyuan Du, Zhuo Su, Xiaozheng Zheng, Zeming Li
CVPR 2024
We propose HMD-Poser, the first unified approach to recover full-body motions using scalable sparse observations from HMD and body-worn IMUs. In particular, it can support a variety of input scenarios, such as HMD, HMD+2IMUs, HMD+3IMUs, etc.
-
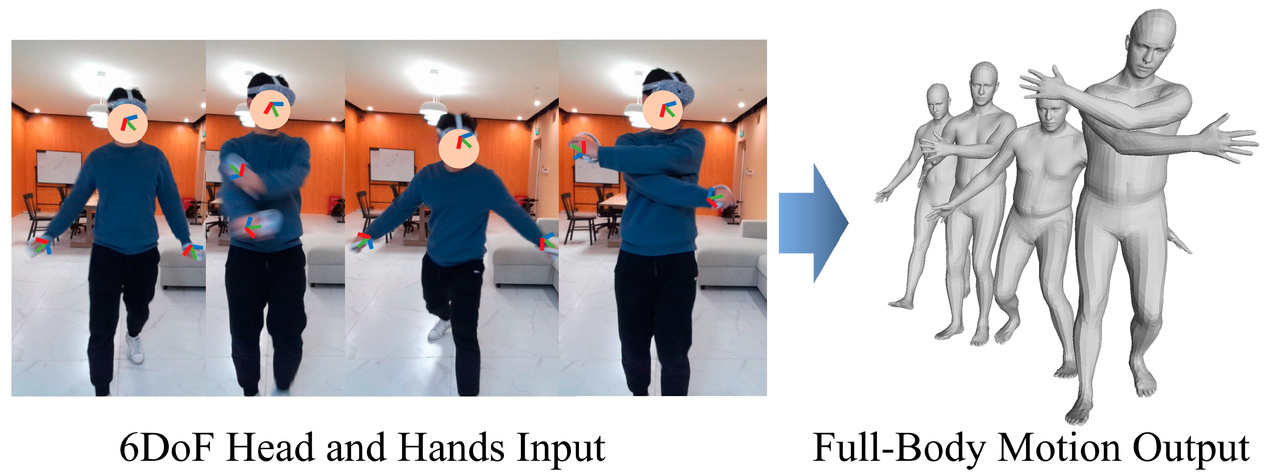
Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling
Xiaozheng Zheng*, Zhuo Su*, Chao Wen, Zhou Xue, Xiaojie Jin
ICCV 2023
We propose a two-stage framework that can obtain accurate and smooth full-body motions with the three tracking signals of head and hands only, in which we first explicitly model the joint-level features and then utilize them as spatiotemporal transformer tokens to capture joint-level correlations.
-
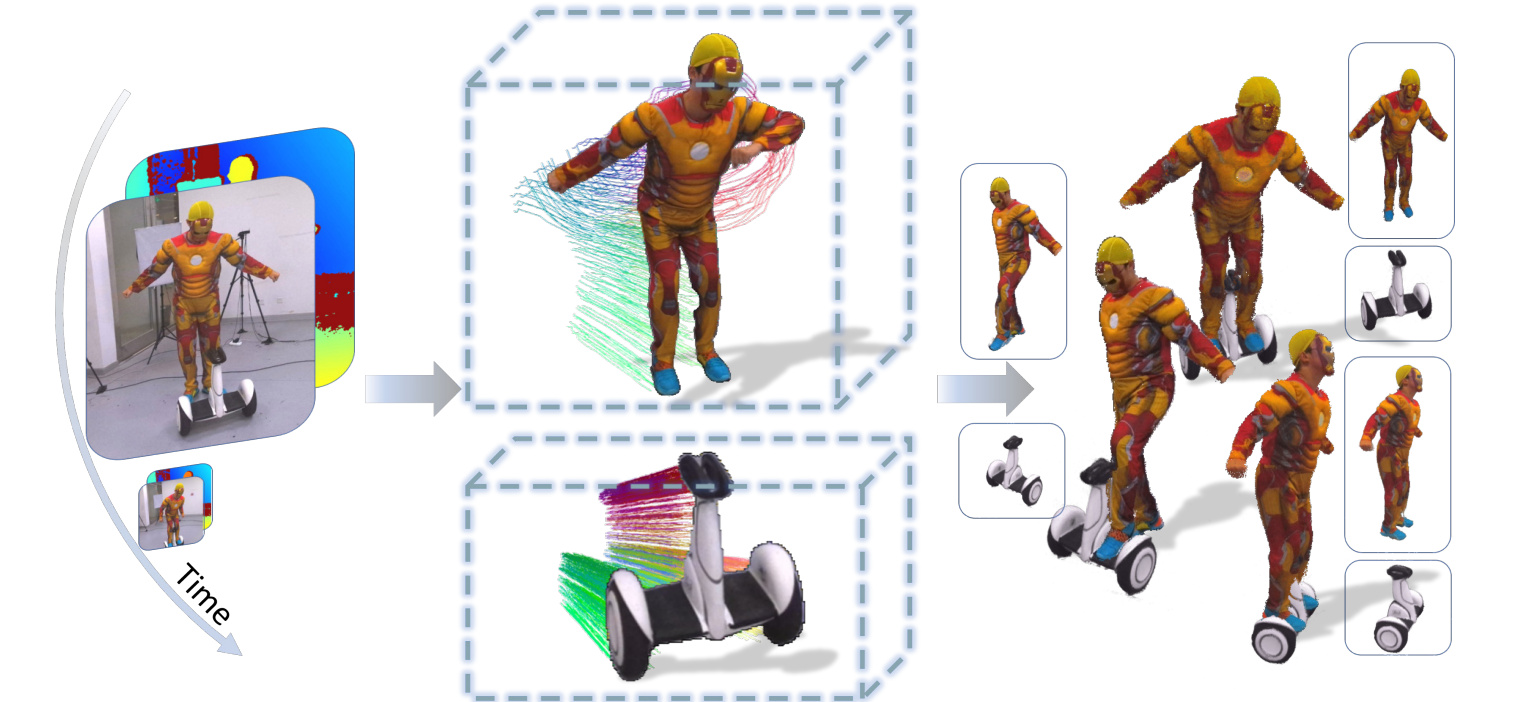
Instant-NVR: Instant Neural Volumetric Rendering for Human-object Interactions from Monocular RGBD Stream
Yuheng Jiang, Kaixin Yao, Zhuo Su, Zhehao Shen, Haimin Luo, Lan Xu
CVPR 2023
We propose a neural approach for instant volumetric human-object tracking and rendering using a single RGBD camera. It bridges traditional non-rigid tracking with recent instant radiance field techniques via a multi-thread tracking-rendering mechanism.
-

Robust Volumetric Performance Reconstruction under Human-object Interactions from Monocular RGBD Stream
Zhuo Su, Lan Xu, Dawei Zhong, Zhong Li, Fan Deng, Shuxue Quan, Lu Fang
TPAMI 2022
We propose a robust volumetric performance reconstruction system for human-object interaction scenarios using only a single RGBD sensor, which combines various data-driven visual and interaction cues to handle the complex interaction patterns and severe occlusions.
-
NeuralHOFusion: Neural Volumetric Rendering Under Human-Object Interactions
Yuheng Jiang, Suyi Jiang, Guoxing Sun, Zhuo Su, Kaiwen Guo, Minye Wu, Jingyi Yu, Lan Xu
CVPR 2022
We propose a robust neural volumetric rendering method for human-object interaction scenarios using 6 RGBD cameras, achieving layer-wise and photorealistic reconstruction results of human performance in novel views.
-
Learning Variational Motion Prior for Video-based Motion Capture
Xin Chen*, Zhuo Su*, Lingbo Yang*, Pei Cheng, Lan Xu, Gang Yu
arXiv 2022
We propose a novel variational motion prior (VMP) learning approach for video-based motion capture. Specifically, VMP is implemented as a transformer-based variational autoencoder pretrained over large-scale 3D motion data, providing an expressive latent space for human motion at sequence level.
-

RobustFusion: Human Volumetric Capture with Data-driven Visual Cues using a RGBD Camera
Zhuo Su, Lan Xu, Zerong Zheng, Tao Yu, Yebin Liu, Lu Fang
ECCV 2020 (Spotlight)
We introduce a robust human volumetric capture approach combined with various data-driven visual cues using a Kinect, which outperforms existing state-of-the-art approaches significantly.
-

UnstructuredFusion: Realtime 4D Geometry and Texture Reconstruction using Commercial RGBD Cameras
Lan Xu, Zhuo Su, Lei Han, Tao Yu, Yebin Liu, Lu Fang
TPAMI 2019
We propose UnstructuredFusion, which allows realtime, high-quality, complete reconstruction of 4D textured models of human performance via only three commercial RGBD cameras.
- "Face image relighting methods, devices, equipment, media and program products", CN: 202511853077
- "Three-dimensional head portrait generating method, apparatus, device, storage medium and program product", CN: 202511534921
- "Image generation methods, apparatus, devices, media and program products", CN: 202511073112
- "Method and apparatus for pose estimation, and electronic device", US20250028385A1
- "Information processing method, device, terminal and storage medium", CN: 202410823369
- "Pose estimation method, device and electronic device", CN: 202310896769
- “Dynamic three-dimensional reconstruction method, device, equipment, medium and system”, CN:201910110062:A
- “Texture real-time determination method, device and equipment for dynamic scene and medium”, CN:201910110044:A
- “Dynamic human body three-dimensional reconstruction method, device, equipment and medium”, CN:202010838902:A
- “Dynamic human body three-dimensional model completion method and device, equipment and medium”, CN:202010838890:A
- “Depth Camera-based three-dimensional renconstruction method and apparatus, device, and storage medium”, US201916977899A
- “Depth camera calibration method and device, electronic equipment and storage medium”, CN:201810179738:A
- “A three-dimensional rebuilding method and device based on a depth camera, an apparatus and a storage medium”, CN:201810179264:A
-

Human-Centric Capture and Digitalization for Immersive XR Experiences
This talk presents recent advances in human-centric capture and digitalization for XR, highlighting progress in motion capture, 3D reconstruction, performance capture, and avatar creation. We discuss how these pipelines work together to faithfully represent human motion, appearance, and behavior in virtual environments. By unifying these elements, we show how real people can be faithfully brought into immersive virtual worlds to enable true presence.
Aug. 13, 2025, SIGGRAPH, Vancouver | Technical Workshop
-

Towards Deployable High-Fidelity Avatars: A 3D Modeling Framework Powered by Scalable Real-World Data
The deployment of high-fidelity 3D avatars is often hindered by the profound gap between ideal lab conditions and chaotic real-world inputs. This work tackles this "Reality Gap" by exploring a scalable, data-driven modeling framework tailored for practical user scenarios. Spanning from foundational data synthesis and illumination decoupling to flexible Large Reconstruction Models, I share this exploration to demonstrate how we are powering truly deployable digital humans.
Apr. 17, 2026 China3DV, Hangzhou | Young Scholar Forum
-

Human Motion Capture and Avatar Creation using Sparse Observations
The development of high-fidelity 3D human motion capture and avatar reconstruction is essential for immersive experiences in XR applications. This line of work explores modeling under sparse observation settings, tackling the challenges posed by limited sensors and minimal image inputs. The research spans from multi-modal motion understanding to generalizable avatar generation, and I share this exploration with the hope of contributing to the XR technologies.
Apr. 11, 2025 China3DV, Beijing | Young Scholar Forum
- PICO "Star Team Award" Innovation Breakthrough Award (创新突破奖 ), Bytedance, 2023
- Tencent Open Source Collaboration Award (腾讯开源协同奖 ), Tencent, 2021
- Outstanding Graduate of Beijing (北京市优秀毕业生 ), Beijing, 2021
- Outstanding Graduate of Department of Automation, Tsinghua University, 2021
- Excellent Bachelor Thesis Award, Northeastern University, 2018
- Outstanding Graduate of Liaoning Province, Liaoning Province, 2018
- National Scholarship, Ministry of Education, 2018
- Excellence Award for National Undergraduate Innovation Program, Northeastern University, 2017
- City's Excellent Undergraduate, Shenyang City, 2017
- Mayor's Scholarship, Shenyang City, 2017
- Top Ten Excellent Undergraduate (10 / the whole university, 十佳本科生 ), Northeastern University, 2017
- Honorable Mention of American Mathematical Contest in Modeling, COMAP, 2017
- Second Prize of National Undergraduate Mathematical Contest in Modeling, CSIAM, 2016
- First Prize of Provincial Undergraduate Mathematical Contest in Modeling, Liaoning Province, 2016
- 2x Second Prize of Electronic Design Contest, Education Department of Liaoning Province, 2015-2016
- 4x First Class Scholarships, Northeastern University, 2015-2018
Applications
Avatar Creation and XR Telepresence
This line of work includes 8 patents, with technology transfer to XR avatar and holographic telepresence products for realistic human representation and interaction in virtual environments.
Public patents include:
Motion Capture and Human Motion Understanding
This line of work includes 3 patents, with successful technology transfer to real-world XR products including Pico Motion Tracker, enabling precise and accessible full-body motion tracking in consumer virtual reality.
Public patents include:
Dynamic Human Reconstruction
This line of work includes 4 patents, with technology transfer to industrial partners and deployment in products such as fitness measurement and related 3D human-centric applications.
Public patents include:
Static Reconstruction and SLAM
This line of work includes 3 patents, with technology transfer to industrial partners including smartphone manufacturers, and deployment in navigation, AR effects, and related mobile 3D vision scenarios.
Public patents include:
Invited Talks
Academic Conference
Industry Forum
ByteTech Technical Sharing Series

Revolutionizing XR MoCap: Sparse to Multi-Modal, Environment-Aware
This talk reviews four representative works — AvatarJLM, HMDPoser, EnvPoser, and EMHI — showcasing advances from sparse IMU modeling and egocentric sensing to multi-modal fusion and environment-aware inference, pushing sparse motion capture toward practical XR applications.
Jun. 5, 2025, ByteDance, Online Live Stream

Human 3D Reconstruction and Generation
The rconstruction of realistic 3D human is crucial in VR/AR applications. This talk focuses on 3D human modeling, covering topics from traditional volumetric capture to neural rendering, from per-scene optimization to generalizable prior model training and generative methods.
Dec. 26, 2024, ByteDance, Online Live Stream